因为airflow1.0和2.0变更了许多
接下来会通过分析airflow1.0和airflow2.0的源码来加深对airflow的理解
airflow简介
airflow是一个工作流模式的分布式任务调度框架,可以实现复杂的工作流调度。因为工作原因需要对airflow进行调研,因此这里记录一下学习airflow过程遇到的问题并吸收一些实现技巧。接下来会根据airflow的各种组件,深入airflow的源码进行讲解。airflow从1.0到2.0,实现的架构进行了一次较大的改变,因此,我在这里同时分析两个大版本的源码,通过分析其中的异同,也可以一窥开发者的设计思路和优化方向。
首先放一张整体的airflow架构图
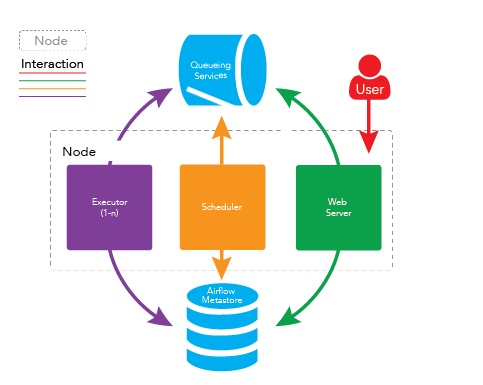
2.0和1.0在整体结构相似,这里大概会将airflow的解析分为调度器篇 worker(executor)篇 dag处理器篇 webserver篇
接下来的内容默认读者对airflow的基本概念有一定的了解,如果尚未了解相关内容,之后有时间我再考虑写一篇概念相关内容
airflow创建工作流的过程主要如下,注意airflow是一个命令驱动的框架,几乎所有的机制都是从发送命令行开始的
- 通过命令行创建
dag和operator, - 配置
airflow的基本配置,包括数据库连接,webserver端口,连接板并发数,读取的存放dag文件夹的位置等等 - 启动调度器,
webserver以及executor,这时框架会自动从设置好的的dag文件夹位置读取dag和operator的配置文件并生成dag和task存放进数据库 - 接着就可以登陆
airflow的webserver查看各个dag的运行情况l
airflow1.0 调度器部分
这里我们选择的版本是1.8.2
首先观察一下airflow的主要结构
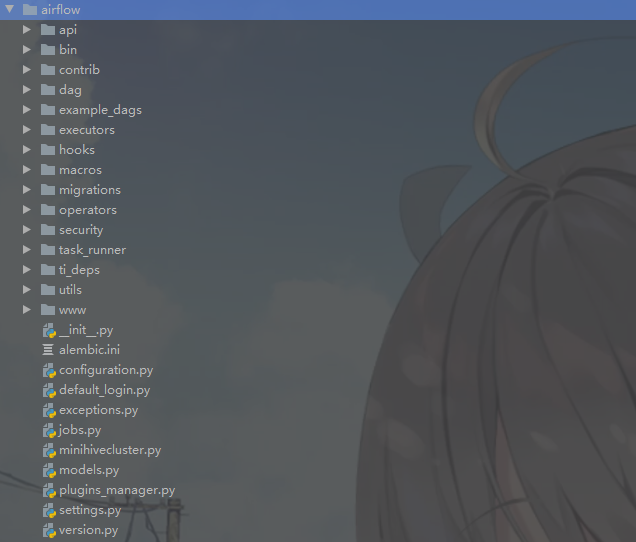
大致解释一下各个目录的作用
api: 放置了一些用于代码内接口调用的方法bin:启动方法contrib:应该是一些第三方插件的定制方法,包括sensor,executor,hook等dag:dag的基类example_dag: 一些dag的样例模板executor:具体的executorhooks:用于方法内调用的hook,使得可以降低非核心功、能的耦合程度macros:只有hive的一些方法,我还不是特别了解migrations: 略operators:定制的一些operator,即task的模板security:有关用户认证和登录的方法task_runner: 执行airflow命令行工具,有点像bashti_dep: taskinstance 的一些依赖状态utils: 工具类www: 页面相关
可以看到目录结构非常之多,因此我们需要抓住一条主线来梳理。本篇选择以调度器作为切入口,我们就从调度器的创建开始吧。
airflow所有机制的运行入口几乎都是从命令行开始的,因此我们直接从命令行的入口方法查看,这里我们查看/bin/cli.py
可以看到再cli.py的CLIFactory类中存在大量的命令定义,这里在之后的学习中还会经常回到这里。我们直接查看scheduler的启动
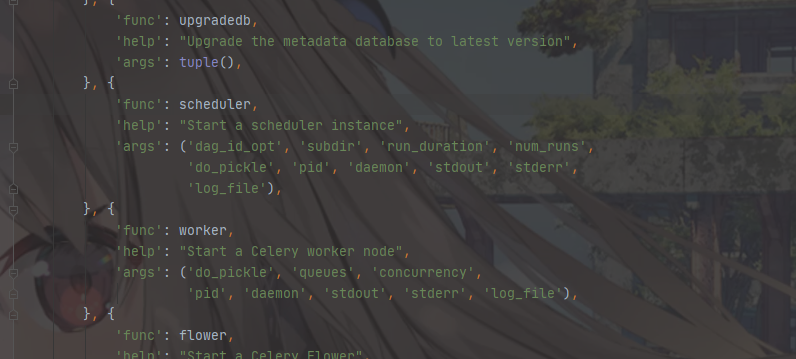
1 | def scheduler(args): |
可以看见,核心在于创建schuedulerJob类,同时传入dag_id, 持续时间,并发数等基本参数
继续进入,可以发现我们跳转到了job.py
我们先查看一下schedulerJob的父类,baseJob.py
1 | class BaseJob(Base, LoggingMixin): |
可以发现,这里job首先是作为一张表保存了job的状态,执行情况(这里是sqlalchemy的相关知识)
主要的方法有
is_alive: 通过heartbeat判断是否存活kill:通过删除数据库记录的方式来结束任务on_kill:等待子类重写,用于删除任务的时候做一些额外处理heartbeat_callback:心跳的回调,等待子类重写heartbeat:发送心跳,下面详细介绍run:修改表中job的状态,来表示job正在进行,同时执行_exexute_execute: 等待子类重写,如何执行jobreset_state_for_orphaned_tasks:重置孤儿任务
下面我们看看heartbeat
1 | def heartbeat(self): |
心跳在调度器运行期间定期发送,通过查表判断调度器状态是否正常
1 |
|
重置孤儿任务则是考虑在调度过程可能因为各种异常情况,如调度器进程突然中止或者没有没有执行器执行任务,就会产生无法继续执行的孤儿任务,这种任务将会在下一次调度前进行回收并再次调度
接下来就进入schedulerJob了,我们直接来看核心方法
1 | def _execute(self): |
可以看到调度的流程是 加锁-> 获取解析后的dag -> 调度 ->调度结束杀死进程
关于解析dag我们单独放一篇出来讲,这里我们直接进入execute_helper一探究竟
1 | def _execute_helper(self, processor_manager): |
内容有点长,主要可以分成这几部分
- 处理前调度的特殊情况
- 调度和解析dag
- 执行task-instance
- 调度结束后处理
先看调度前
1 | self.executor.start() |
这里会首先寻找dag-run,dag-run是dag每次执行生成的实例,通过dag-run清理之前调度器遗留下来的孤儿任务
除了孤儿任务,首先看调度前有哪些依然正常运行的任务
- dag-run有效同时task-instance还在调度中(schedue),这些可以直接被本次调度回收
- dag-run有效同时task-instance还在进入队列中(queued),这些会被队列回收
因为
airflow2.0调度器部分
airflow2.0因为使用python3作为开发语言,因此在架构上使用了许多新的特性,同时整体的文件组织结构也发生了较大的变化