像是经历了一次漂流,最终依然要选择回归现实

记录一次工作中遇到的GC分配失败问题
之前在工作中遇到一次IO占用异常的情况,通过iotop查看IO占用最高的进程,发现都是业务相关的java进程,于是通过查阅gc.log发现了类似如下的异常(图源网络,当场场景已不可复现, 当时场景与下图几乎类似)
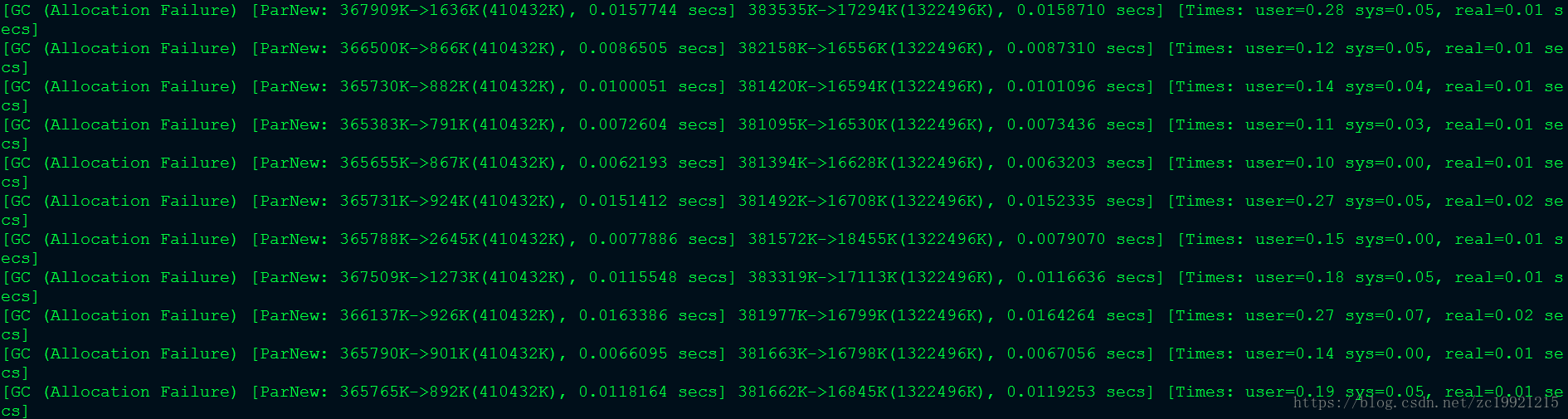
问题最关键的是异常一直在输出,这让人不由得怀疑业务逻辑中存在的问题,事实上,通过这些,导致问题的原因其实已经能比较容易就能联想到,但是,本着务实求真(大雾)的态度,还是要细细了解其中出现的个中缘由
基础概念
既然看到了内存分配的字样,我们首先自然得先复习一下JVM内存分配的基础概念。
我们知道,JVM中采用分代的内存分配策略,将java堆分成了新生代,老年代。仔细分的话,新生代又能分成eden区和survivor区(分为0和1两个区域,这也是为了更好的进行垃圾回收,比如使用复制算法)

一个对象从创建之初就有两种选择
- 小对象进入新生代
- 大对象进入老年代
我们以小对象举例,在进入新生代后,对象首先会被分配到eden区,在这个过程中,就会经历到垃圾回收(GC)。GC又分为minor GC和fullGC(还有major GC,这里不作解释,通常可以认为是fullGC等价)minorGC仅进行新生代范围的垃圾回收,因为范围少,所以回收快,一般不会对执行中的进程 造成很大影响(视收集器算法而不同,minor GC也会暂停线程工作,导致STW),当eden区满后,就会执行一次minorGC, 经过一次minorGC之后,如果对象存活,就会进入survivor区
survivor区的对象存活时间会稍长,因为当存活对象经历了数次GC之后(默认是15次,每进行一次对象年龄+1),对象才会进入老年代。
大对象和经历数次回收的对象存活在老年代,这里区域很大,数据变动也不频繁,代价就是垃圾回收的时候影响很大。如果老年代区域空间占满导致full GC,就会stop the world(暂停当前所有线程工作,会影响任务执行)
至此,一个对象从出生到死亡的整个过程就结束了。现在回到开始,我们可以通过查看gc.log来观察对象内存分配情况
1 | [GC (Allocation Failure) [ParNew: 367523K->1293K(410432K), 0.0023988 secs] 522739K->156516K(1322496K), 0.0025301 secs] [Times: user=0.04 sys=0.00, real=0.01 secs] |
这是其中一条记录。我们分别看看这些参数代表什么含义:
GC:代表进行了一次垃圾回收,前面没有full修饰,说明是minor GC,因此单论这次GC,本身不会对任务造成太大影响·
Allocation Failure: 结合上面的minor GC可以得出此次内存分配失败是新生代没有足够的空间导致的,因此会触发minor GC,让部分对象进入老年代
parNew 说明这次GC发生在新生代,同时使用的收集器是parNew收集器,ParNew是一个Serial收集器的多线程版本,会使用多个CPU和线程完成垃圾收集工作,该收集器采用复制算法回收内存,期间会停止其他工作线程,造成STW。
之后的参数代表 GC前内存区域使用容量->GC后内存区域使用容量(内存区总容量) 后面的时间代表耗时
接着又是一组数据,代表堆区垃圾回收前的大小->堆区垃圾回收后的大小(堆区总大小) 以及该内存区域GC耗时
最后的Times则是总耗时,分别代表 用户态耗时 内核态耗时 总耗时
分析下可以得出结论:
- 该次
GC新生代减少了367523-1293=366239K Heap区总共减少了522739-156516=366223K
366239 – 366223 =16K,说明该次共有16K内存从年轻代移到了老年代,可以看出来数量并不多,说明都是生命周期短的对象,只是这种对象有很多。
我们需要的是尽量避免Full GC的发生,让对象尽可能的在年轻代就回收掉,所以这里可以稍微增加一点年轻代的大小,让那17K的数据也保存在年轻代中。
(这里介绍几个修改JVM的参数)
排查方法
这里针对排查java出现的异常,做一下简单的命令行记录。
jdk内置了若干命令行工具,这些命令在 JDK安装目录下的 bin目录下:
jps(JVM Process Status): 类似UNIX的ps命令。用户查看所有 Java 进程的启动类、传入参数和 Java 虚拟机参数等信息;jstat( JVM Statistics Monitoring Tool): 用于收集HotSpot虚拟机各方面的运行数据;jinfo(Configuration Info for Java) : 显示虚拟机配置信息;jmap(Memory Map for Java) :生成堆转储快照;jhat(JVM Heap Dump Browser ) : 用于分析heapdump文件,它会建立一个 HTTP/HTML 服务器,让用户可以在浏览器上查看分析结果;jstack(Stack Trace for Java):生成虚拟机当前时刻的线程快照,线程快照就是当前虚拟机内每一条线程正在执行的方法堆栈的集合。
jps
显示虚拟机执行主类名称以及这些进程的本地虚拟机唯一 ID(Local Virtual Machine Identifier,LVMID)
*注意:必须要在进程执行的对应用户权限下操作
1 | C:\Users\SnailClimb>jps |
参数
jps -l:输出主类的全名,如果进程执行的是 Jar包,输出 Jar路径
jps -q:只输出进程的本地虚拟机唯一 ID
jps -v : 输出虚拟机进程启动时候JVM参数
jps -m: 输出传递给main函数的参数·
jstat
使用于监视虚拟机各种运行状态信息的命令行工具
1 | jstat -<option> [-t] [-h<lines>] <vmid> [<interval> [<count>]] |
jstat -class vmid:显示ClassLoader的相关信息;jstat -compiler vmid:显示JIT编译的相关信息;jstat -gc vmid:显示与GC相关的堆信息;jstat -gccapacity vmid:显示各个代的容量及使用情况;jstat -gcnew vmid:显示新生代信息;jstat -gcnewcapcacity vmid:显示新生代大小与使用情况;jstat -gcold vmid:显示老年代和永久代的信息;jstat -gcoldcapacity vmid:显示老年代的大小;jstat -gcpermcapacity vmid:显示永久代大小;jstat -gcutil vmid:显示垃圾收集信息;jstat -t: 在输出信息上加一个Timestamp列,显示程序的运行时间。
jinfo
输出当前 jvm 进程的全部参数和系统属性 (第一部分是系统的属性,第二部分是 JVM 的参数)。
*使用 jinfo 可以在不重启虚拟机的情况下,可以动态的修改 jvm 的参数
1 | C:\Users\SnailClimb>jinfo -flag MaxHeapSize 17340 |
jinfo -flag [+|-]name vmid : 开启或者关闭对应名称的参数。
1 | C:\Users\SnailClimb>jinfo -flag PrintGC 17340 |
jmap
用于生成堆转储快照.dump文件,除此之外生成dump文件的方法还有
-XX:+HeapDumpOnOutOfMemoryError参数让虚拟机在OOM异常出现之后自动生成dump文件Linux命令下可以通过kill -3发送进程退出信号也能拿到dump文件
1 | C:\Users\SnailClimb>jmap -dump:format=b,file=C:\Users\SnailClimb\Desktop\heap.hprof 17340 |
jhat
用于分析 heapdump文件,它会建立一个HTTP/HTML服务器,让用户可以在浏览器上查看分析结果。
1 | C:\Users\SnailClimb>jhat C:\Users\SnailClimb\Desktop\heap.hprof |
jstack
用于生成虚拟机当前时刻的线程快照。线程快照就是当前虚拟机内每一条线程正在执行的方法堆栈的集合.
·查找耗时时间长的线程的通用方法:
- 使用
jps查找出java进程的pid,如7777
或ps -ef | grep java - 使用
top -p 7777观察进程情况,然后Shift+h,显示该进程的所有线程。 - 找出
CPU消耗较多的线程``id,如7788,将7788转换为16进制0x1e6c`,注意是小写。 - 使用
jstack 7777 | grep -A 10 0x1e6c来查询出具体的线程状态。-A 10表示查找到所在行的后10行
结语
现在有了这些知识储备,相信解决一些常见问题应该不会无从下手了。现在返回到最上面的问题。当时出现了一直打印内存失败的信息,首先判断出这是minor ``GC,如果出现频率低那可以暂时不用考虑,属于正常现象;但是依然需要去思考优化如何减少GC。这次的问题在于一直在有对象进入老年代,可见如果持续i下去,内存必然占满。因此,很可能是代码逻辑出现了问题,例如死循环等,让任务一直不断执行,不断生成新对象,消灭老对象。最后查看代码逻辑,果然定位到了问题所在。
当然,如果是经验丰富的老手一定能在第一时间判断出问题的根源。但是我依然还在不断学习,还是需要通过记录的方式,总结经验,提升能力。