jsoup是一个用于处理真实HTML的Java库。它提供了一个非常方便的API,用于提取和操作数据,使用最好的DOM,CSS和类似jquery的方法。
目录
- jsoup概述
- 使用场景
- DOM解析
- CSS选择器
- HTML过滤
- 逻辑分析
- 总结
jousp概述
官方解释:
jsoup是一个用于处理真实HTML的Java库。它提供了一个非常方便的API,用于提取和操作数据,使用最好的DOM,CSS和类似jquery的方法。
个人接触到Jsoup是在用java写爬虫时,苦恼于大量使用正则匹配不仅降低了代码的可读性,相对也比较费时费力。这时候,一款爬虫框架突然映入眼帘,那就是jsoup。
作为一款轻量,功能强大的爬虫框架,jsoup让简单抓取网页信息变得优雅,便捷。 虽然是一个java库,但是它的使用逻辑却无比接近于jQuery,以至于只要是熟悉或是了解JQuery的人可以轻而易举地上手这款框架。
使用场景
DOM解析
jsoup的dom解析异常简单吗,只需要new一个ducumnet对象即可实现获取这个网页元素,接下来以解析一个网页为例。可以看到,将网页转化成ducument类,之后的Element类以及其子类都可以看成是一个个节点,通过调用相关方法实现整个文件节点的遍历。同时,Element类的getElementByTag让人很容易联想到js中的相关方法,因此只要有点JS基础和java基础的人看这段代码都不会觉得陌生。 这里以查询学生成绩信息为例:
1 | public class jsoupTest { |
结果:
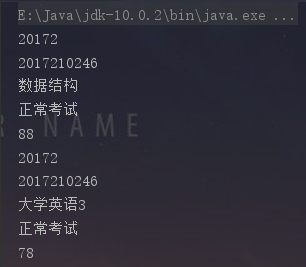
只需要几行就可以完成对html的基本解析,而且所有的操作都可以用js的逻辑解释。或多或少比原生正则匹配要实用的多。
CSS选择器
jsoup决心是想向前端靠齐了,除了基本的DOM解析操作外,它同时加入了CSS选择器,这个操作乍一看似乎没什么用处,但是当你真正去学习如何使用后你的就会发现这是多少好用。在针对较复杂地语句匹配时,使用选择器可以轻而易举地筛选出你想要的元素,可以帮你节省大量代码。 使用方法:可以用Element.select(String selector)和Element.select(String selector)实现.
1 | public void getBySelect() throws IOException { |
结果:
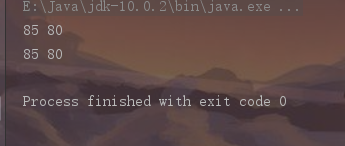
CSS选择器类似于JQuery和CSS中使用的选择器,可以通过特定的选择器语法将对指定元素进行筛选 对于选择器的筛选,这里推荐一篇文章:详解JSOUP的Select选择器语法 (链接已失效)
HTML过滤
这个功能也是偶然看见的,不过现在想来也理所当然,过滤网页信息本身就是Jsoup分内的事。当时正在看XSS攻击方面的知识,突然发现jsoup在安全方面已早有考虑,已本身优秀的HTML解析为基础,抵御XSS攻击自然也是十分优秀。
XSS注入本质就是在HTML中插入特定的标签改变原来标签的含义,因此防止XSS攻击的本质是能分辨并及时过滤掉多余或是无效的HTML标签。对此,jsoup有一个白名单机制,通过clean方法可以一步通过白名单设置的过滤规则清理所有的标签,同时也会保留适当标签和禁止图片显示的功能。
1 | /** |
逻辑分析 jsoup
作为一款轻便的爬虫框架,全部由Jonathan Hedley独立写出,因此代码相比其他一些笨重的框架要简洁很多,我通过网上一些解析jsoup源码的博客,加深对jsoup的理解。废话不多说,让我们看看jsoup的魅力吧!
借用别人博客里整理的图片,可以看到,让java能像js那样使用类似标签的嵌套存储的方法就是在这里就是利用自定义的node抽象类,将属性存储在类似树状的结构中这,这样做不仅有利于之后的DOM树解析,也容易遍历,有利于性能的提高。 我们再看看CSS选择器的实现逻辑。这是selector的源码列表
jsoup在关于selector的实现大致是利用Evaluator抽象类,Selector选择的表达式都会通过QueryParser最终编译到对应的Evaluator类上,然后此类又有很多派生子类,从而分别实现不同功能。逻辑思路还算简单,但是具体代码我还不曾仔细研读,因此在此也不再赘述。不过其中进行嵌套实现对象的思路还是值得借鉴的。
在HTML过滤方面,jsoup防止XSS攻击的大致策略是
- 将HTMl字符串解析成document对象,这样保证了无法通过注入一段无用的脚本和字符串拼接导致网页的功能发生了改变
- 将一些高频出现的危险系数较高的标签加入白名单进行提前过滤
总结
jsoup在操作便捷度上已经展现了它的实力,但是在性能上,考虑到它的底层还是通过正则进行匹配,因此对于一些一些简单的HTML解析或许直接正则的最快的;但是,当HTML页面比较复杂,这便是jsoup大显身手的时候了。
但是jsoup还是有很多不足,例如
- 只能处理静态页面,对于动态显示或者后端渲染后后的页面无法正常进行爬取,这时就需要利用其他的工具例如httpunit进行模拟的ajax请求。
- jsoup总归还只是个人项目,在后期的维护方面还是存在一定的不确定性,如果需要用应用在一些大型的长久性的项目中还需三思。
- jsoup的底层实现还是正则匹配,尽管jsoup本身够轻量,但它依然需要解析整个HTML,再进行进一步的搜索,因此在一些简单的网页解析中,肯定还是直接上正则来的直接来的方便。但是如果网页的结构足够复杂,使用正则的的代码量巨大,那么jsoup不失为一个不错的选择。
总而言之,jsoup作为一款轻量的爬虫框架,在HTML解析方面的表现还是很不错的,如果平时希望偷点懒,节省点时间和代码量,完全推荐大家使用。