01月
10
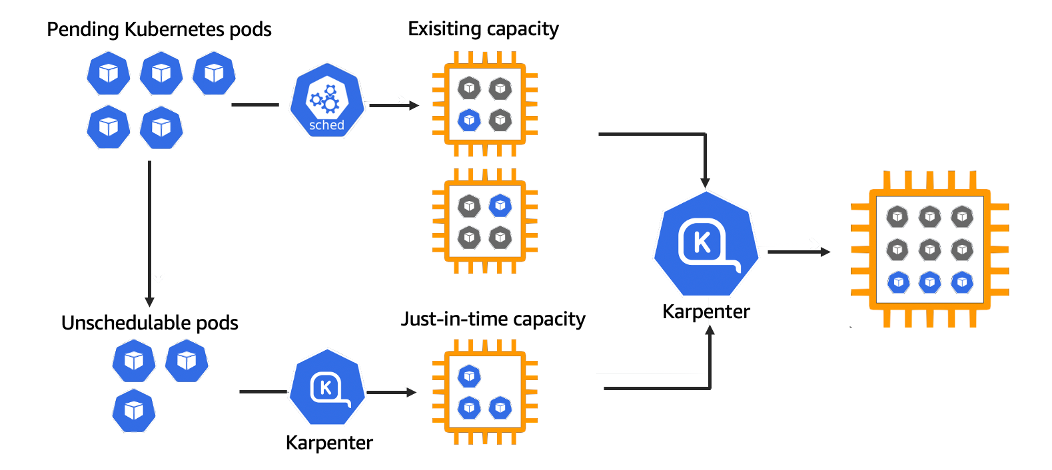
Karpenter是一个AWS提供的节点生命周期管理器,它会观察传入的pod并根据情况启动正确的节点。节点选择决策基于策略并由传入的pod的规范驱动,包括资源请求和调度约束。
它的主要作用:
Karpenter观察未调度的Pod的聚合资源请求,并做出启动和终止节点的决定,以最大限度地减少调度延迟和基础设施成本。
优势
karpenter provisioner 的模板
1 | apiVersion: karpenter.sh/v1alpha5 |
同时需要配置node template 模板
1 | apiVersion: karpenter.sh/v1alpha5 |
利用Karpenter的分层约束模型,pod运行受到三层约束
第一层由云服务器厂商对硬件的类型,区域进行限制;第三层由其他技术控制pod调度;Karpenter通过设置Provisioner对指定节点进行调度和决策,从而满足第二层的控制
通过Provisioner 可以做到的限制包括
Karpenter 控制节点上下线的方式包括以下几种,
在aws中可以代替固定节点组的创建,基于taint以及 亲和性反亲和性,指定更灵活的策略进行节点的调度与约束
MapReduce作为至今仍为流行的大数据计算框架,虽然早已在各个场景下均有竞品,但是凭借大保有量和集群较高的升级成本,现在依然在行业上占有较大规模。然而,随着技术不断迭代,以及用户对数据降本越来越高的需求,即使上层计算不变,下层配套设施比如存储,比如容器都可能会往更弹性,更经济的方向演进,从而会让计算在异构环境下运行的情形越来越多。
周末和朋友去看了《第二十一条》。这片本来不在我的观影列表之内,之前大致了解过是老谋子拍的电影,题材是法律相关。要是换做几年前或许我还会抱有较高期待,但是近年老谋子拍的电影数量很多,但大多偏商业,内容参差不齐,这难免让我对他的新作会抱有更谨慎的态度。
不过说内容参差不齐还略有些不妥当,但确实就近几年他的作品质量总是会引发不小的讨论,例如之前春节档上映的《满江红》,虽然很多人批评这部片整体质量偏低,也有很多人认为这部片很好看,市场反馈也很不错。究竟是什么原因会导致老谋子的作品总是争议不断,我始终抱有这个疑问。不过这次看了《第二十一条》,心里大致也有了答案。